Reporting and communication
For every file, document, or employee, you can create and follow-up on tasks via workflows, ensuring that progress can be easily tracked. This way, you, your employees, and your clients always know what is expected. You can also communicate with contacts and send mailings and invitations.






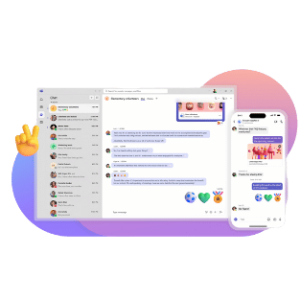





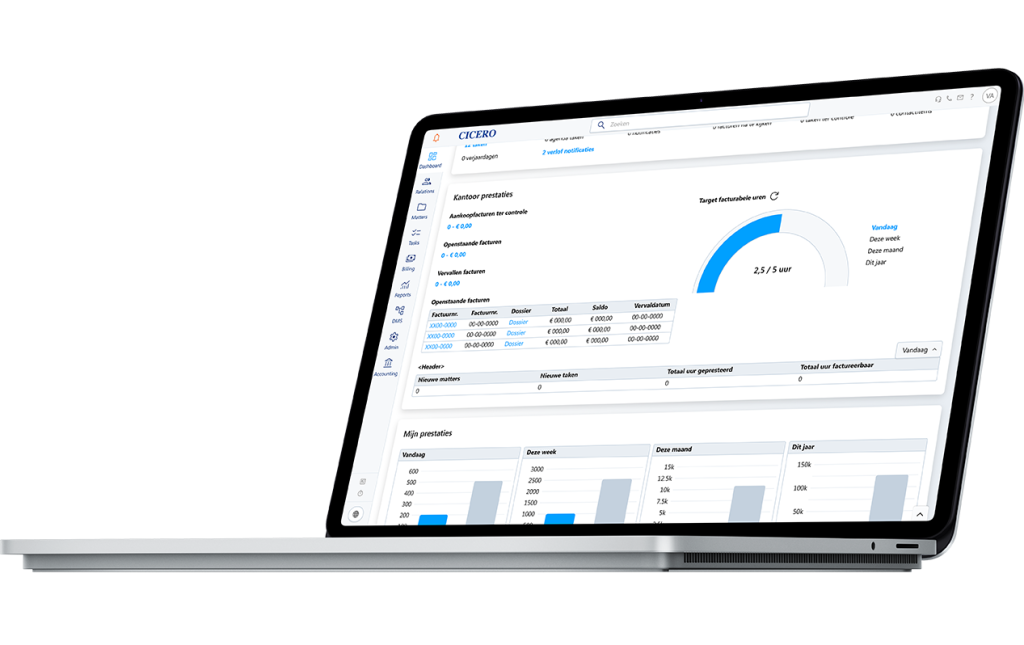


It's not just the follow-up of debt collection cases, but the overall ease of use: the system comes with loads of templates, but it's just as easy to create your own. Whenever you give a call or send an email, you're assisted immediatedly.
Ann Vandermotten Gaius Advocaten